
Lokale KI ausprobieren: Ollama einfach aufsetzen
Künstliche Intelligenz ist längst nicht mehr nur ein Thema für Forschungseinrichtungen oder große Tech-Konzerne. Dank moderner Tools wie Ollama kann heute jeder mit leistungsfähigen Sprachmodellen (LLMs) direkt auf dem eigenen Rechner experimentieren. Ganz ohne Cloud-Anbindung oder komplizierte Infrastruktur.
Was ist Ollama und wozu dient es?
Ollama ist eine leichtgewichtige Laufzeitumgebung für Large Language Models (LLMs), also große Sprachmodelle wie LLaMA 3, Mistral, Phi, oder Gemma. Diese Modelle sind darauf trainiert, natürliche Sprache zu verstehen und zu erzeugen – etwa um Texte zu schreiben, Code zu generieren oder Fragen zu beantworten.
Das Besondere an Ollama: Es erlaubt dir, solche Modelle lokal auszuführen. Das bedeutet, deine Daten bleiben auf deinem Rechner, du brauchst keine Internetverbindung nach außen, und du hast volle Kontrolle über das Modell.
Damit ist Ollama ein ideales Werkzeug für Entwickler, die mit KI experimentieren oder eigene Anwendungen testen wollen.
Ergänzend gibt es grafische Oberflächen wie Ollama WebUI oder Open WebUI, die dir eine komfortable Chat-Oberfläche im Browser bieten – ähnlich wie ChatGPT, nur dass alles lokal läuft.
Installation von Ollama
Die Einrichtung von Ollama ist schnell erledigt. Je nach Betriebssystem geht das folgendermaßen:
macOS und Linux:
Öffne ein Terminal. Führe folgenden Befehl aus:
curl -fsSL https://ollama.com/install.sh | sh
Nach Abschluss kannst du prüfen, ob Ollama läuft:
ollama run llama3
Windows:
- Lade den Installer von ollama.com/download herunter.
- Folge dem Installationsassistenten.
- Ollama lässt sich auf zwei weisen starten
- Eingabeaufforderung oder PowerShell und gib ein:
ollama run llama3
- Windows Taste und “Ollama” suchen und starten
Nachdem Ollama das gewünschte Modell (z. B. LLaMA 3) beim ersten Start heruntergeladen hat, steht es für lokale Chats oder Integrationen bereit. Wenn man Ollama über den Eintrag im Startmenü bzw. das App-Icon startet, öffnet sich eine Chat-Oberfläche, die stark an bekannte Web-UIs wie ChatGPT oder Gemini erinnert.
Der wesentliche Unterschied: Ollama führt die LLMs lokal auf deiner eigenen Hardware aus, statt Anfragen an einen Cloud-Dienst zu senden. Neue Modelle können direkt aus der Chatoberfläche heraus gesucht und hinzugefügt werden, oder über die zentrale Modellbibliothek unter https://ollama.com/library.
Dort finden sich Varianten der gleichen Modelle in unterschiedlichen Größen und sogenannten Quantisierungen (z. B. q4, q6, q8), die direkt Einfluss auf Hardwarebedarf und Qualität haben.
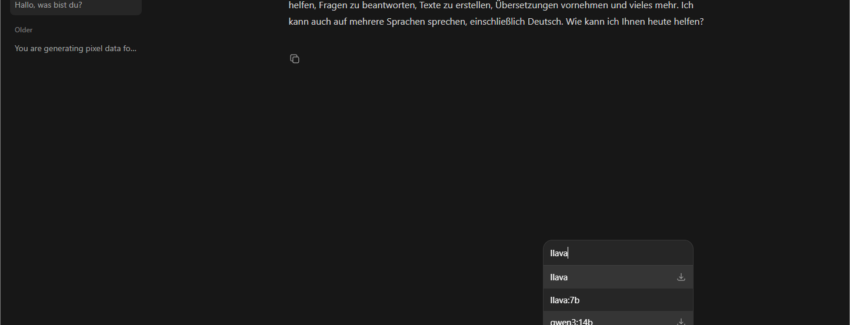
Die Parametergröße und die Quantisierung beschreiben zwei unterschiedliche Aspekte eines Modells – grob gesagt: wie „groß/klug“ es ist und wie „kompakt“ es gespeichert wird.
Parametergröße (z. B. 3B, 7B, 70B)
- Ein „7B“-Modell hat etwa 7 Milliarden Parameter – das sind die inneren Stellschrauben, die das Modell beim Training lernt.
- Mehr Parameter bedeuten:
- Das Modell kann komplexere Muster erkennen und mehr Wissen speichern.
- Es liefert meist bessere, nuanciertere Antworten, braucht aber mehr RAM/VRAM und läuft langsamer.
- Weniger Parameter:
- Modell ist kleiner, schneller und genügsamer bei der Hardware.
- Dafür etwas eingeschränkter bei komplexem Denken und Fachwissen.
Quantisierung (z. B. q4, q6, q8)
- Quantisierung bedeutet: Die gespeicherten Zahlen im Modell werden mit weniger Genauigkeit abgelegt, um Speicher zu sparen. Statt „feinen“ 16/32‑Bit-Werten nutzt man grobere Stufen wie 4‑Bit.
- Effekte:
- Niedrige Stufe (z. q4):
- Modell benötigt deutlich weniger RAM/VRAM und läuft auf schwächerer Hardware.
- Die Antworten können minimal ungenauer oder „rauschiger“ werden.
- Höhere Stufe (z. q8):
- Bessere Qualität, näher am Originalmodell.
- Braucht entsprechend mehr Speicher und Rechenleistung.
Warum sich das Ausprobieren lohnt
Mit Ollama kannst du die Funktionsweise moderner KI praktisch nachvollziehen – ohne Cloud, ohne Gebühren, aber mit vollem Zugriff auf deine Modelle. Ob du verstehen möchtest, wie LLMs auf Eingaben reagieren, oder erste eigene Ideen mit KI-Unterstützung testen willst: Eine lokale Ollama-Installation ist der perfekte Startpunkt, um die Grundlagen moderner Sprachmodelle zu erforschen und spielerisch ein Gefühl für deren Möglichkeiten zu entwickeln.