
KI einfach erklärt: Vom ersten Lernschritt bis zur smarten Benutzeroberfläche
Am Anfang war das Modell… und der (verbrannte) Toast
Bevor eine KI Vorhersagen treffen kann, muss sie etwas Grundlegendes lernen: Strukturen in Daten erkennen.
Das geschieht im sogenannten Modelltraining.
Stell dir vor, du möchtest einer KI beibringen, ob ein Toast verbrannt ist oder nicht.
Dafür zeigst du ihr sehr viele Fotos von Toastscheiben – einige perfekt goldbraun, andere komplett schwarz. Zu jedem Bild schreibst du dazu, um welche Klasse es sich handelt, z. B.:
- „Dieses Bild = verbrannt“
- „Dieses Bild = nicht verbrannt“
Die KI weiß zu Beginn gar nichts. Sie hat kein Bauchgefühl und keine Vorstellung von Toast. Aber sie kann Muster in den Bildern erkennen:
- Welche Farbwerte häufig bei verbranntem Toast auftreten
- Welche Formen, Kanten oder Texturen typisch sind
- Wie sich helle und dunkle Bereiche im Bild verteilen
- Welche Bildregionen besonders unterschiedlich sind
Jedes Mal, wenn die KI ein Bild sieht, gibt sie eine erste (meist falsche) Einschätzung ab. Danach bekommt sie Rückmeldung:
„Du liegst falsch — dieses Bild war nicht verbrannt. Pass deine Berechnung leicht an.“
Das passiert tausend- oder millionenfach, bis das Modell die Muster so gut gelernt hat, dass seine Vorhersagen zuverlässig werden, desto größer der Datensatz, desto präziser wird das Model.
Dieser Prozess ist wie das wiederholte Schärfen eines Werkzeugs:
Mit jeder Korrektur wird das Modell präziser.
Am Ende entsteht ein trainiertes Modell, also eine Art mathematisches „Gedächtnis“ der gelernten Zusammenhänge:
Welche Muster deuten auf „verbrannt“ und welche eher nicht?
Es handelt sich im Kern um ein riesiges neuronales Netzwerk, dessen viele Millionen oder Milliarden Zahlenwerte (Gewichte) so angepasst wurden, dass sie bestimmte Muster zuverlässig erkennen können.
Das Modell „merkt“ sich nicht die Bilder selbst — es lernt Regeln und Strukturen, die für die Unterscheidung relevant sind.
Zum Trainieren des Models werden Tools wie bspw.:
verwendet.
Und dann kam die Inferenz – der Moment, in dem der Toast sein Urteil bekommt
Nachdem das Modell im Training gelernt hat, verbrannten und unverbrannten Toast anhand von Mustern zu unterscheiden, stellt sich die nächste Frage:
Wie nutzt die KI dieses Wissen eigentlich, um im echten Einsatz Vorhersagen zu treffen?
Oder anders gesagt:
Wie wird die Theorie zur Praxis?
Hier kommt die Inferenz ins Spiel – und mit ihr die Inferenz Engine.
Während das Training der Phase entspricht, in der die KI lernt, ist die Inferenz der Moment, in dem sie anwenden muss, was sie gelernt hat.
Stell dir vor, du gibst der KI nun ein neues Toastbild, das sie noch nie zuvor gesehen hat.
Die KI schaut sich das Bild an, erkennt darin die gelernten Muster – Farben, Kanten, Texturen – und berechnet auf Basis ihrer Gewichte:
„Dieses Muster passt zu verbrannt. Mit 92 % Wahrscheinlichkeit.“
Damit die KI diese Berechnung schnell, effizient und zuverlässig durchführen kann, benötigt sie eine technische Komponente zwischen Modell und Anwendung:
die Inferenz Engine.
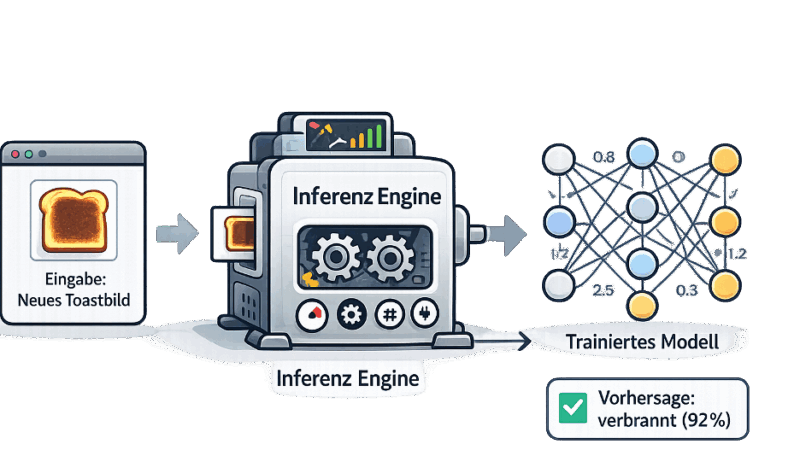
Eine Inferenz Engine übernimmt dabei folgende Aufgaben:
- Sie lädt das trainierte Modell.
- Sie verarbeitet die Eingaben (z. B. das Bild).
- Sie führt die mathematischen Berechnungen des Modells aus.
- Sie liefert die fertige Vorhersage zurück.
Die Inferenz Engine nimmt dabei die Rolle eines Dolmetschers ein, der zwischen Benutzeroberfläche und KI-Modell steht.
Werkzeuge:
Das Userinterface spricht nicht direkt mit dem Modell.
Stattdessen gibt es seine Anfrage an die Inferenz Engine weiter, die speziell dafür entwickelt wurde, die Berechnungen des Modells möglichst effizient auszuführen.
Warum ist das wichtig?
Ein großes neuronales Netzwerk besteht aus Millionen oder Milliarden mathematischer Operationen, die alle gleichzeitig verarbeitet werden müssen. Eine Inferenz Engine sorgt dafür, dass diese Operationen optimiert, beschleunigt und ressourcenschonend ausgeführt werden – egal ob auf einer GPU, CPU oder einem spezialisierten KI-Chip.
Sie passt das Modell an die verfügbare Hardware an, komprimiert es bei Bedarf, und führt Berechnungen so aus, dass die Vorhersage am Ende schnell, präzise und stabil geliefert wird.
Und schließlich das Interface – wo KI für Menschen nutzbar wird
Nachdem wir nun wissen, wie ein trainiertes Modell in der Inferenzphase Vorhersagen trifft, fehlt noch ein letzter Baustein:
Wie kommen diese Vorhersagen überhaupt zum Nutzer?
Denn die wenigsten Menschen interagieren direkt mit einer Inferenz Engine oder geben Rohdaten in eine technische Schnittstelle ein.
Damit KI‐Modelle im Alltag nutzbar werden – zum Chatten, zum Analysieren oder für Automationen – braucht es Benutzeroberflächen, die die komplexe KI-Technik dahinter für uns unsichtbar machen.
Hier kommen Oberflächen wie:
ins Spiel.
Man kann sich diese Oberflächen vorstellen wie Bedienpulte, über die wir Eingaben machen, Fragen stellen oder Dateien hochladen.
Sobald wir etwas eintippen, passiert Folgendes:
- Die Benutzeroberfläche nimmt unsere Eingabe entgegen.
(z. B. eine Frage, ein Bild oder eine Aufgabenbeschreibung) - Sie leitet diese Eingabe an die Inferenz Engine weiter.
– oft lokal, manchmal über einen Server - Die Inferenz Engine führt die Berechnung mit dem Modell durch
- Das Ergebnis wird zurück an die Oberfläche geschickt.
- Die Oberfläche zeigt uns das Resultat an – als Text, Bild, Analyse oder Empfehlung.
Dadurch entsteht ein harmonischer Gesamtfluss:
Modell → Inferenz Engine → Benutzeroberfläche → Nutzer
Die Interfaces sind also nicht selbst „intelligent“, sondern sie sind der Zugangspunkt, der dafür sorgt, dass Menschen KI‐Modelle intuitiv und ohne technisches Vorwissen nutzen können. Sie machen die komplexen mathematischen Abläufe dahinter unsichtbar – und ermöglichen es uns, mit einem Klick oder einer Chatzeile auf die Vorhersagekraft mächtiger Modelle zuzugreifen.