Die klassische Struktur eines Unternehmens sieht ein zentrales Datenmanagement-Team vor, welches für sämtliche Daten-Pipelines, die Datenaufbereitung und die Datenanalyse verantwortlich ist. Dementsprechend weit verbreitet sind zentrale Datenarchitekturen wie beispielweise Data Lakes und Data Warehouses. Für kleinere Unternehmen ist das ein guter Ansatz, da so die Integrität und Konsistenz der Daten auf einfachem Wege gesichert wird. Bei einem wachsenden Unternehmen, mit starker Datenorientierung, d.h. insbesondere bei steigendem Datenvolumen, steigender Anzahl an Datenquellen und datengetriebenen Use-Cases, die alle vom zentralen Datenteam bedient werden möchten und verschiedene Datenstrukturen verwenden, kann dies zu einem Bottleneck führen.
Das zentrale Daten-Team kann auf Dauer die analytischen Fragen in Bezug auf Daten nicht schnell genug bearbeiten. Neben der Instandhaltung der Daten-Pipelines muss das Daten-Team sich mit den Themen der einzelnen Domains befassen, um sämtliche Fragen kompetent beantworten zu können. Die Wettbewerbsfähigkeit wird hierdurch gefährdet.
![]() Sofern nicht anders erklärt, sind mit Daten immer analytische Daten gemeint.
Sofern nicht anders erklärt, sind mit Daten immer analytische Daten gemeint.
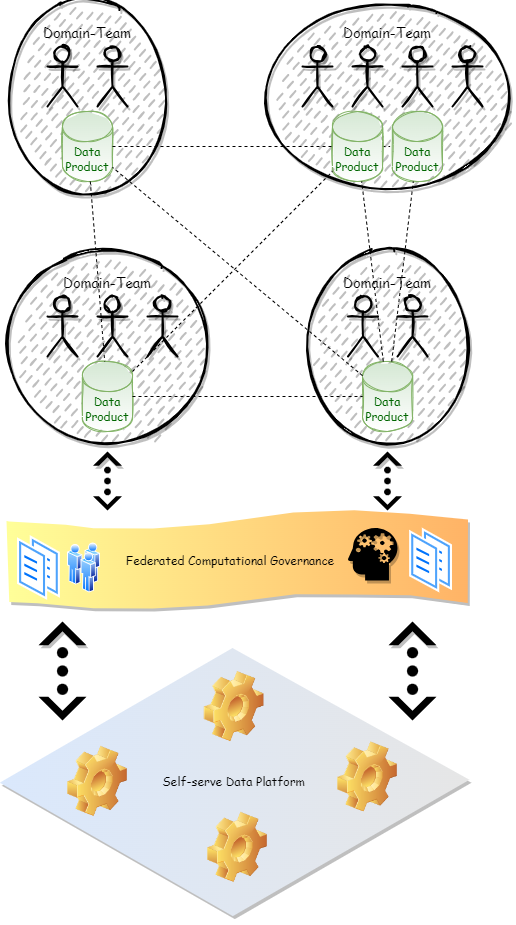
Ein wesentliches Augenmerk beim Data Mesh liegt auf der Dezentralisierung der Datenverwaltung. Das Data Mesh Prinzip bringt die Verantwortung für das Datenmanagement weg vom zentralen Daten-Team und hin zu den Domain-Teams, also näher an die Quelle der Daten. Die Domain-Teams verwalten ihre Daten autonom, befolgen jedoch gewisse Grundsätze und Richtlinien, um die Kooperation zwischen den Domain-Teams zu verbessern und zu erhöhen. Unterstützt werden sie dabei durch eine zentrale Plattform, die die notwendigen Werkzeuge dafür bereitstellt. Dadurch werden einige Schwierigkeiten adressiert, die durch eine Dezentralisierung der Datenverwaltung auftreten können, etwa Mehraufwand, duplizierte Daten oder Inkompatibilität.
![]() Der Ursprung von Data Mesh
Der Ursprung von Data Mesh
Der Begriff Data Mesh wurde im Wesentlichen von Zhamak Dehghani geprägt. Dieser und die folgenden Artikel orientieren sich an dem Artikel „Data Mesh Principles and Logical Architecture“ sowie dem Buch „Data Mesh“ von Zhamak Dehghani.