
![]() Das Wort Ownership ist kurz für Product Ownership. Gemeint ist hiermit die langfristige Verantwortung, Daten wie ein Produkt zu kreieren, zu modellieren, zu pflegen, weiterzuentwickeln und zu verteilen, damit sie den Anforderungen der Datennutzer gerecht werden. Dies ist nicht zu verwechseln mit der Souveränität der Daten. Die Nutzer, Kunden oder andere Organisationen, von denen die Daten gesammelt werden, bleiben die Besitzer der Daten.
Das Wort Ownership ist kurz für Product Ownership. Gemeint ist hiermit die langfristige Verantwortung, Daten wie ein Produkt zu kreieren, zu modellieren, zu pflegen, weiterzuentwickeln und zu verteilen, damit sie den Anforderungen der Datennutzer gerecht werden. Dies ist nicht zu verwechseln mit der Souveränität der Daten. Die Nutzer, Kunden oder andere Organisationen, von denen die Daten gesammelt werden, bleiben die Besitzer der Daten.
Data Mesh folgt den natürlichen Organisationsstrukturen eines Unternehmens. Damit unterscheidet es sich grundlegend von klassischen Ansätzen. Frühere Ansätze orientierten sich oftmals an den technologischen Grenzen. So gab es dedizierte Teams, die sich auf Speichertechnologien, z.B. Datenbanken, Data Lakes und Data Warehouses spezialisierten. Andere Teams konzentrierten sich auf die Erstellung und Wartung von Daten-Pipelines. Zuletzt noch Teams, die die Analyse und Aufbereitung der Daten übernahmen. Ergänzt um Betriebsteams, die alle Teilkomponenten überwachten. Der Vorteil einer technologischen Aufteilung halfen die Komplexität und den Aufwand, der mit dem relativ neuen Feld des analytischen Datenmanagement verbunden ist, auf ein spezialisiertes Team zu beschränken.
Ohne Data Mesh werden beispielsweise Domain Events von Domain Teams in der transaktionalen Datenbank abgelegt, vom zentralen Daten-Team aufgenommen und in einen Data Lake, ein Data Warehouse oder beides gelegt – eine monolithische Datenplattform entsteht. Jenseits der ursprünglichen Bereitstellung übernehmen die Domain Teams keine Verantwortung.
Im Data Mesh erweitert sich die Verantwortung der Domain Teams: Sie sind für die Bereitstellung einer analytischen Sicht der Domain Events verantwortlich und stellen damit die Domänendaten direkt den Datenabnehmern, z.B. den Datenanalysten, Datenwissenschaftlern und anderen Dateninteressenten zur Verfügung.
![]() Dies offenbart einen Schwachpunkt und Komplexitätsfaktor in einem Data Mesh. In einem Data Mesh wird eine verteilte Datenarchitektur eingeführt – verteilte Architekturen sind zwar skalierbar, aber komplexer zu verwalten. Insbesondere für kleine Unternehmen kann das hinderlich sein.
Dies offenbart einen Schwachpunkt und Komplexitätsfaktor in einem Data Mesh. In einem Data Mesh wird eine verteilte Datenarchitektur eingeführt – verteilte Architekturen sind zwar skalierbar, aber komplexer zu verwalten. Insbesondere für kleine Unternehmen kann das hinderlich sein.
Ein wichtiger Input für Data Mesh stammt aus dem Domain-driven Design (DDD). DDD bildet eine wichtige Basis im Bereich der Softwarearchitekturen und nicht zuletzt für manche Microservice-Architektur. Die Idee ist also, einen Schritt weiter zu gehen und auch für die analytischen Daten ein Domänen-orientiertes Design zu entwerfen.
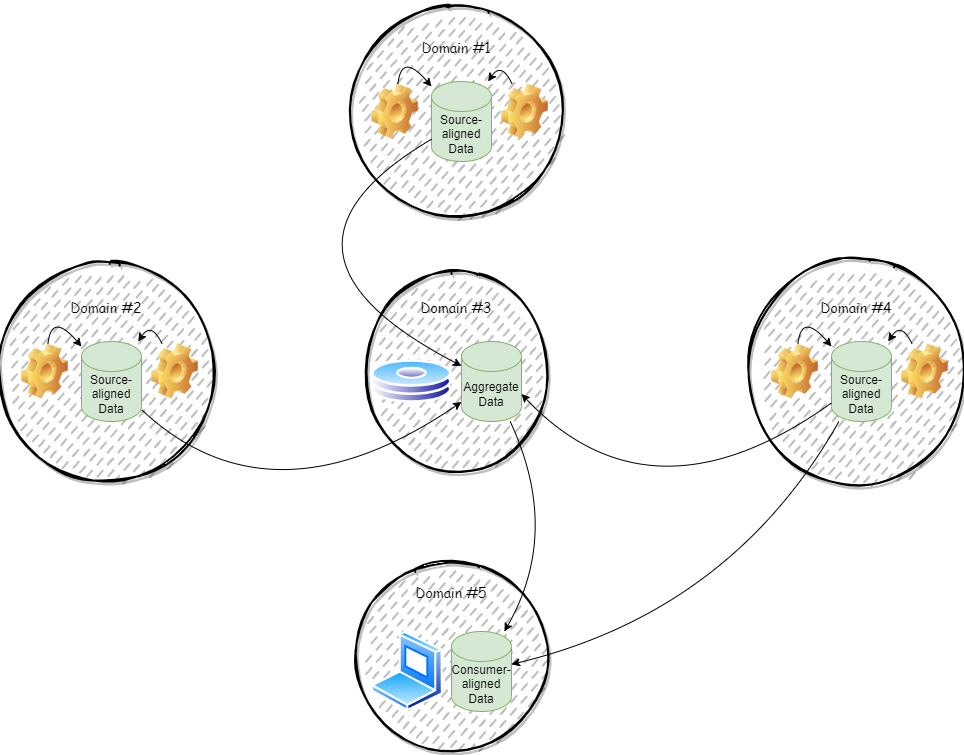
Beim Data Mesh-Prinzip wird zwischen drei verschiedenen Archetypen von Domain-orientierten Daten unterschieden:
- Source-aligned Domain Data: Source-aligned Domain Data ist der grundlegendste Archetyp: Er repräsentiert die Fakten und Wahrheiten des Unternehmens. Diese können jederzeit genutzt werden, um wertvolle Daten/Aggregationen zu generieren. Dieser Archetyp ist als rohe Daten zu sehen, die noch nicht auf einen bestimmten Konsumenten zugeschnitten sind, im Gegensatz zu den anderen beiden Archetypen.
Diese Daten bestehen aus Fakten, generiert von operativen Systemen, idealerweise als Domain Event. Die Domain-Teams sind verantwortlich dafür, diese Fakten/Wahrheiten als Source-aligned Domain Data bereitzustellen. Zu beachten ist jedoch, dass dabei eine Trennung zwischen operativen und analytischen Daten erhalten bleibt. Es soll kein direkter Zugriff auf analytische Daten über die transaktionale Datenbank freigegeben werden. Auf Basis der operativen Daten leiten die Domain Teams sinnvolle und aufbereitete analytische Daten ab. Dies steht im Gegensatz zur Verwaltung der operativen Daten, wo Schnelligkeit von zentraler Bedeutung ist.
Im Anschluss wird Source-aligned Domain Data (in der Regel von anderen Domain-Teams) verwendet und weiterverarbeitet und mit Wert angereichert. - Aggregate Domain Data: Aggregate Domain Data besteht aus zusammengeführten Daten mehrerer Domains. Oftmals liefern mehrere Systeme/Domains einen Teil der Daten, woraus sich dann ein Datenkomplex bildet, welcher auf einem Konzept beruht. Source-Aligned Domain Data von verschiedenen Domains fließt zusammen und bildet ein Konstrukt, aus welchem ein Mehrwert generiert werden kann. Hierbei sollte darauf geachtet werden, dass keine 360°-Konzepte entstehen, die alle Aspekte und Facetten versuchen einzufangen. Solche riesigen Datenkonstrukte sind zu komplex, schwer zu verwalten und zu verstehen und bringen die Nachteile mit sich, die man mit Data Mesh versucht zu umgehen. Stattdessen sollen die Endverbraucher der Daten jeweils möglichst ihre eigenen fit-for-purpose Datenkomplexe entwerfen und der Versuchung von großen, ambitionierten, vielseitig verwendbaren Datenkonstrukten widerstehen.
 Aus diesen Gründen ist eine große Anzahl an Aggregate Domain Data-Konstrukten als Anti-Pattern zu sehen. Genauso stellt auch die Aggregation von Daten aus zu vielen Domänen ein Anti-Pattern dar.
Aus diesen Gründen ist eine große Anzahl an Aggregate Domain Data-Konstrukten als Anti-Pattern zu sehen. Genauso stellt auch die Aggregation von Daten aus zu vielen Domänen ein Anti-Pattern dar. - Consumer-aligned Domain Data: Auch fit-for-purpose Domain Data genannt. Das sind Daten, die nur noch wenig bis keine Aufbereitung benötigen, um genutzt zu werden.
Die Domain-Teams, die diese Daten besitzen, versuchen in der Regel eine kleine Gruppe oder einen speziellen Use Case damit zu bedienen. Im Gegensatz zu Source-aligned Domain Data durchläuft Consumer-aligned Domain Data meist mehr Veränderung und transformiert die Domain Events zu Inhalten, die zu einem speziellen Use Case passen. Die Daten sollten so verarbeitet sein, dass die Konsumenten der Daten diese nutzen können, auch wenn sie über weniger technisches Wissen in Bezug auf Daten verfügen.
Der Übergang zu Domain Ownership, einer dezentralen Verantwortung für Daten, ist als Prozess zu betrachten. Ein Data Mesh wird nicht von heute auf morgen implementiert werden. Im Folgenden sind drei Aspekte beschrieben, an denen man sich orientieren kann:
- Verantwortung für Daten näher an die Quelle rücken & eindeutig festlegen: Oftmals gilt die Annahme, dass Daten stromaufwärts weniger wertvoll sind. Data Mesh bezweifelt das. Source-aligned Domain Data kann direkt vom operativen System der Source Domain zu seinen Kollaborateuren und zu benachbarten analytischen Data Products fließen. Stromabwärts kann dann die Verarbeitung, Optimierung und Transformation zu Aggregate Domain Data, bzw. fit-for-purpose Data stattfinden. Diese Transformationen werden im Kontext der stromabwärts liegenden Domains und unter deren langfristigen Verantwortung vollzogen.
Es finden keine intelligenten Transformationen zwischen den Domains im Niemandsland, heute als Daten-Pipelines bezeichnet, statt. - Mehrere, verknüpfte Modelle definieren: Die Idee eines Modells, welches von allen Domains genutzt wird und mittels Data Warehouse Techniken von zentralen Datenverwaltung-Teams beherrscht wird, ist nur im Ansatz gut, wie die Erfahrung gezeigt hat. Es zeigt sich, dass in Wirklichkeit die Welt der Daten zu komplex ist und Systeme sich kontinuierlich verändern.
Data Mesh hingegen verfolgt den Bounded Context, nach Vorbild des Domain Driven Designs. Jede Domain modelliert ihre Daten gemäß ihres Kontexts.
Hierdurch können verschiedene Modelle entstehen, die das gleiche Konzept abbilden wollen, doch das ist in Ordnung. Solche globalen Konzepte mit Domain-spezifischen Attributen nennt man auch Polyseme. Es gibt verschiedene Wege, um Kompatibilität zu gewährleisten, etwa mittels einer globalen Polysem-ID – Beispiele hierfür wären Benutzer-ID oder Produktnummer. Diese Modelle münden schließlich in der Komponente Data Product, welche im nächsten Artikel behandelt wird.
Diese Modelle münden schließlich in der Komponente Data Product, welche im nächsten Artikel behandelt wird. - Daten-Pipelines in der internen Implementierung der Domains verstecken: Beim Übergang zu Data Mesh sollen die verschiedenen Daten-Pipelines und deren Aufgaben auf die Domain-Teams verteilt werden. In Data Mesh sind Daten-Pipelines Implementierungsdetails. Die komplexen Datentransformationen und -bewegungen werden innerhalb der Domains bewerkstelligt. Dies entspricht der Aufbereitung der Domain Events, für die die jeweiligen Source-aligned Domain-Teams verantwortlich sind, sodass stromabwärts diese Daten konsumiert werden können.
Man könnte nun einwenden, dass ein größerer Aufwand dadurch entsteht, dass die Domain-Teams jeweils ihre eigene Dateninfrastruktur zur Speicherung, Aufbereitung und Bereitstellung und einen eigenen Tech Stack aufbauen müssen. Dieses Problem adressiert Data Mesh mit dem Grundprinzip Self-serve Data Platform.